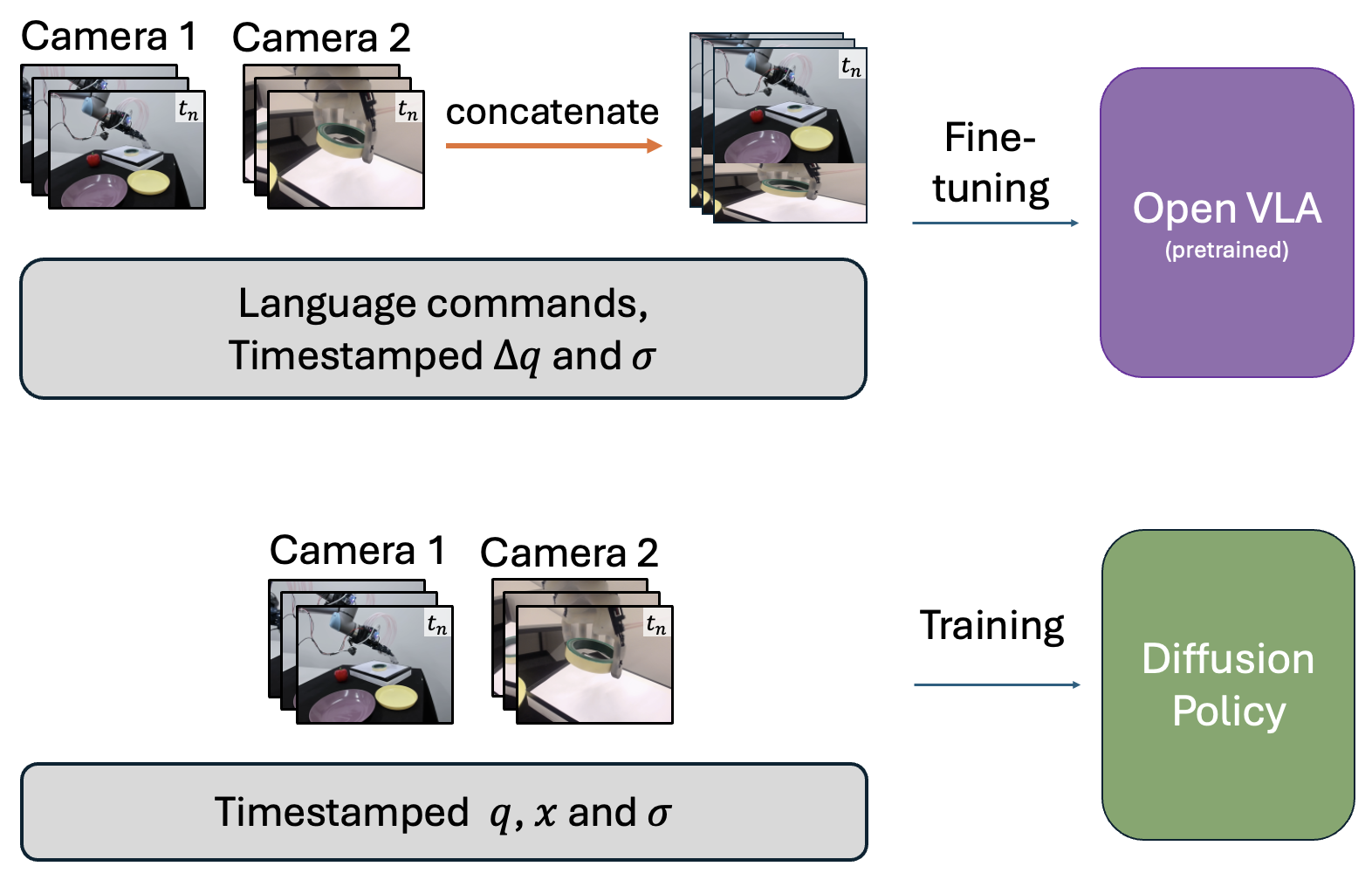
To advance autonomous dexterous manipulation, we propose a hybrid control method that combines the relative advantages
of a fine-tuned Vision-Language-Action (VLA) model and diffusion models.
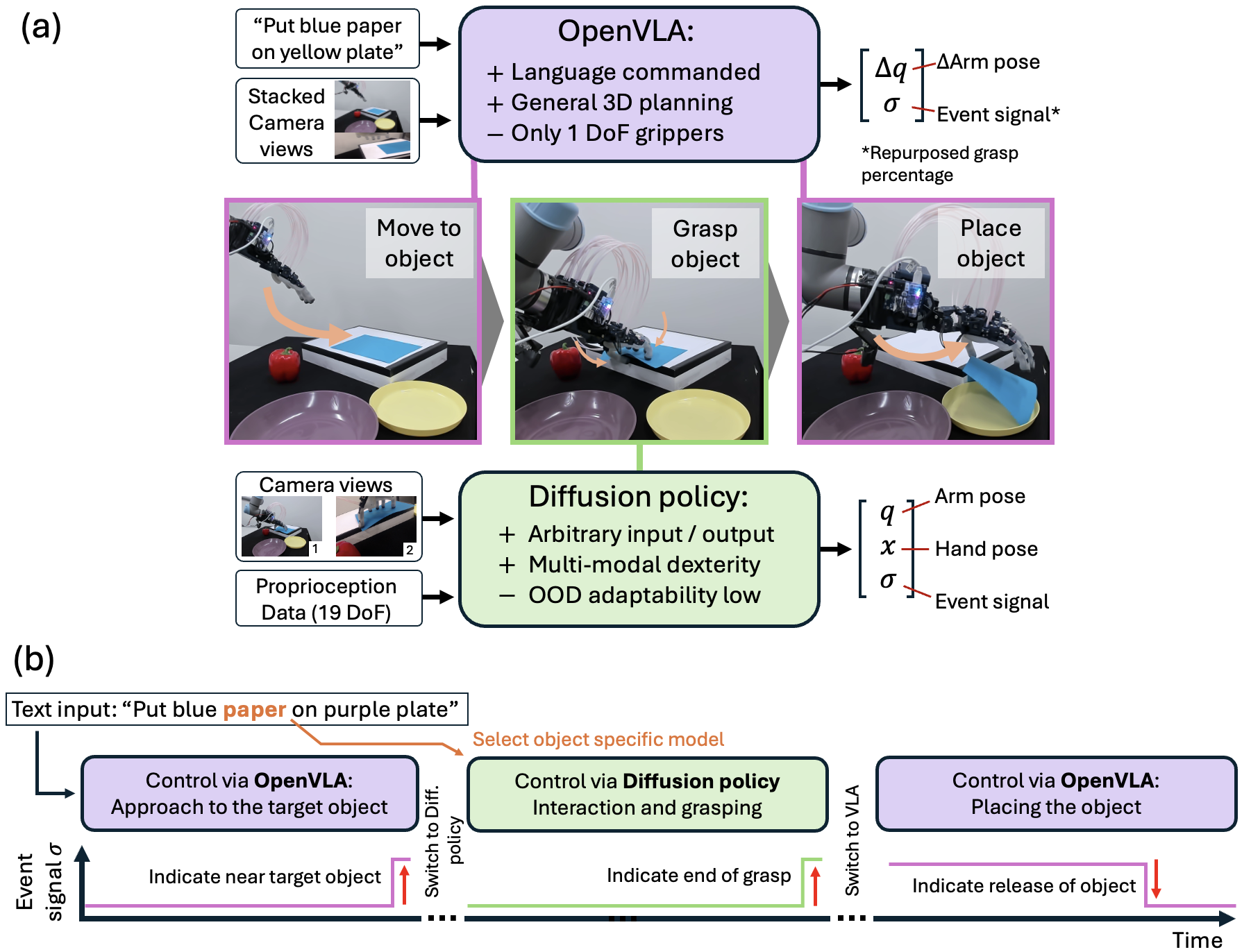
The VLA model provides language commanded high-level planning, which is highly generalizable,
while the diffusion model handles low-level interactions which offers the precision and robustness
required for specific objects and environments. By incorporating a switching signal into the
training-data, we enable event based transitions between these two models for a pick-and-place task
where the target object and placement location is commanded through language.
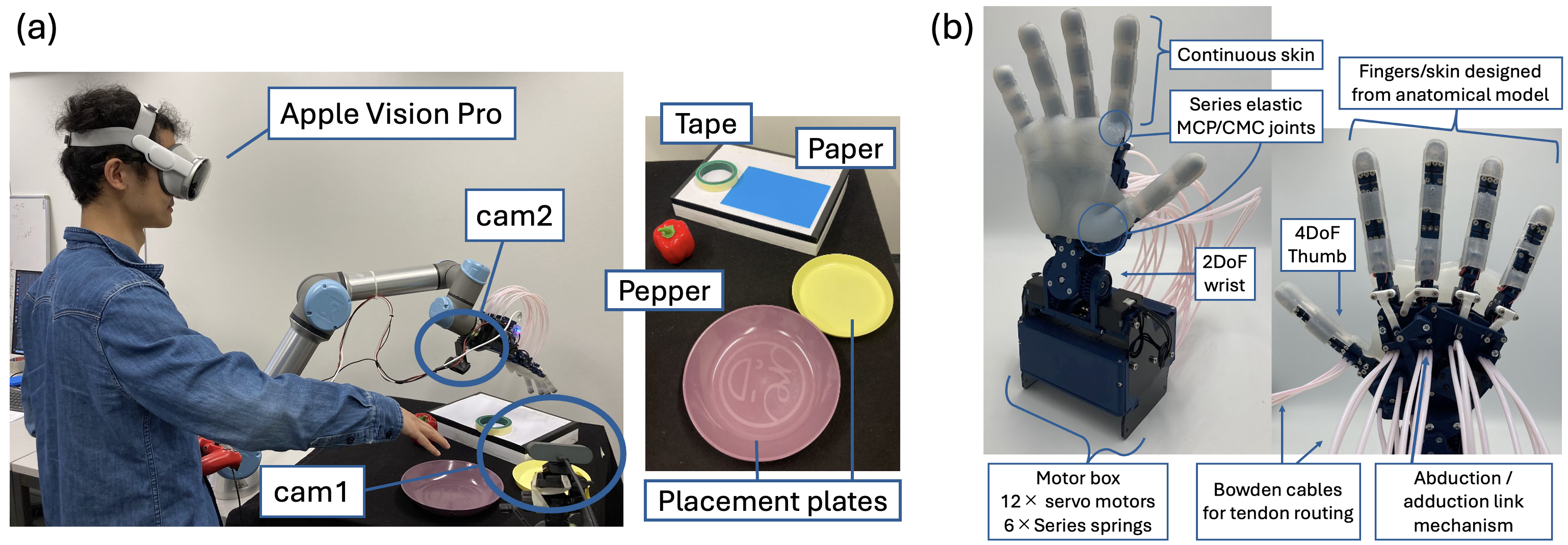
This approach is deployed on our anthropomorphic ADAPT Hand 2, a 13DoF robotic hand,
which incorporates compliance through series elastic actuation allowing for resilience for any interactions:
showing the first use of a multi-fingered hand controlled with a VLA model.
We demonstrate this model switching approach results in a over 80% success rate compared to under 40% when only
using a VLA model, enabled by accurate near-object arm motion by the VLA model and a multi-modal grasping
motion with error recovery abilities from the diffusion model.